
在上一篇文章中,有提到純函數 (Pure Function) 的優點是可預測、易於測試、可推理,雖然實際應用中無法將全部程式碼轉為純函數,但我們可以盡可能提高純函數的比例,而要如何提高純函數的比例呢? 其中一個要了解的就是不可變性(Immutability),如果日常開發都能保持不可變性,就能讓程式有更多純函數,而不可變性就是今天的主題。
純函數的第二條定律是「沒有任何可觀察的副作用」,而最常見也最容易被忽略的副作用,就是修改傳入的參數。如果我們不小心修改了傳入的物件或陣列,即使函式回傳了正確的值,它也已經污染了外部的狀態,不再是純函數了。
不可變性 (Immutability) 的核心概念很簡單:一個資料一旦被創建,就不應該再被更改。當你需要修改資料時,你應該做的是創建一個包含修改的新資料副本。這個原則正是確保函式純粹性的關鍵實踐。
另外,在看如何在 JavaScript 中實踐不可變性之前,稍微補充一下,雖然我們在 JavaScript 中需要自己手動實踐不可變性,但在許多 FP 語言(如 Haskell、Clojure)中,不可變性是程式語言的預設特性,這讓撰寫純函數變得更自然和安全。
const 的陷阱在 JavaScript 中,可能有人會以為以 const 宣告的變數就代表了不可變性,但這是一個常見誤解,const 只能保證變數的賦值 (assignment) 不會被改變,但它完全無法阻止你修改物件的屬性或陣列的內容。
const user = { name: 'Alice', age: 30 };
const hobbies = ['reading', 'hiking'];
// 以下操作是完全合法的
user.age = 31;
hobbies.push('swimming');
console.log(user); // { name: 'Alice', age: 31 } <-- 🔺 物件被修改了
console.log(hobbies); // ['reading', 'hiking', 'swimming'] <-- 🔺 陣列被修改了
可以從上面範例看到,即使是用 const 宣告變數,物件和陣列依然是可變的 (mutable)。
關於什麼是 immutable、什麼是 mutable,在我之前的 React 筆記文章 [React] 了解 immutable state 與 immutable update 方法 有稍微介紹過~有興趣的可以看看,簡單來說,在 JavaScript 中,原始型別(primirive)的資料是 immutable (不可變的)的,immutable 是指這些值本身不能被修改,若希望更新資料,只能「產生一個新值來取代舊的」。而相對於原始型別,JavaScript 中的物件與陣列是以「參考(reference)」形式存在的資料,物件或陣列本身的內容是可變(mutable)的,修改其屬性或項目內容的操作稱為「mutate」。
也因此我們所謂的「不可變性」會針對內容可變的物件和陣列來討論,去思考如何實現 JavaScript 物件和陣列的不可變性。
要在 JavaScript 中實踐物件和陣列的不可變性,我們需要遵守一個核心原則。
首先,我們可以將對資料的操作分為三類 :
user.name。user.name = 'Bob' 或使用 array.push()。array.pop(),它會移除並回傳最後一個元素。其中,「寫入」和「讀取兼寫入」的操作是可變性的來源。而「寫入時複製 (Copy-on-Write)」就是專門用來處理這些操作的原則。
它的實作包含三個明確的步驟:
以一個購物車的 addItem 函式來說,他會先讀取 shoppingCart 資料,然後複製 shoppingCart 的資料副本,再來會修改新的副本,最後回傳這個被修改過的副本,這樣就可以保持 shoppingCart 資料的不變性。

圖 1 寫入時複製示意圖(資料來源: 自行繪製)
再來用一個簡單舉例來看看有寫入時複製和沒有的差異,以下程式目的是為使用者的興趣清單新增一個項目
const user = {
name: 'Bob',
hobbies: ['coding', 'music']
};
function addHobby(user, newHobby) {
// 🔺 直接修改了傳入的 user 物件中的 hobbies 陣列
user.hobbies.push(newHobby);
return user;
}
const user = {
name: 'Bob',
hobbies: ['coding', 'music']
};
function addHobby(user, newHobby) {
// 步驟 1 & 2: 建立 user 物件的副本,並在副本上修改 hobbies
const newUser = {
...user,
hobbies: [...user.hobbies, newHobby] // 同時也複製了 hobbies 陣列
};
// 步驟 3: 回傳全新的物件
return newUser;
}
const updatedUser = addHobby(user, 'gaming');
console.log(user.hobbies); // ['coding', 'music'] <-- ✅ 原始資料保持不變
console.log(updatedUser.hobbies); // ['coding', 'music', 'gaming']
需要特別注意的是,展開語法 (...) 或 Object.assign() 執行的都是淺拷貝(Shallow Copy)。淺拷貝的意思是它只會複製巢狀物件或陣列的第一層資料結構,兩個巢狀資料會分享下層的資料參照,稱為「結構共享(structural sharing)」。
而淺拷貝這種只複製第一層,巢狀內層資料仍共享的狀況,可能會為我們的程式帶來一些意外危險,舉例如下:
const original = {
name: 'Carol',
address: { city: 'Taipei' }
};
const copy = {...original };
// 修改副本的深層屬性
copy.address.city = 'Kaohsiung';
console.log(original.address.city); // "Kaohsiung" <-- 🔺 原始物件被意外修改了!
original.address.city 的內容被意外修改,原因是因為 copy 和 original 物件雖然是不同的物件,但它們內部的 address 屬性指向的是同一個記憶體位置。

圖 2 copy 和 original 物件的 address 屬性指向相同記憶體位置(資料來源: 自行繪製)
可能有人看到這裡會想說,那解法就使用深拷貝吧~所謂深拷貝就是將巢狀資料的每一層資料結構都複製出來,兩個巢狀資料完全不共享任何內容,但深拷貝其實不是最有效率的做法,要實踐巢狀資料的不可變性,我們只需複製需要修改的路徑。
比較好的做法是,在修改 city 之前,我們需要先為 address 也建立一個副本:
const original = {
name: 'Carol',
address: { city: 'Taipei' }
};
// 1. 複製第一層
const copy = {...original };
// 2. 複製要修改的第二層
copy.address = {...original.address };
// 3. 在第二層的副本上修改
copy.address.city = 'Kaohsiung';
console.log(original.address.city); // "Taipei" <-- ✅ 原始物件保持不變
這種「只複製修改路徑」的策略之所以會更好,是因為剛剛我們說的「結構共享 (structural sharing)」的概念。當我們創建 copy 時,copy.name 和 original.name 其實共享了同一個 Carol 字串的參照。同樣的,在第二個範例程式中,copy.name 依然和 original.name 共享參照,我們只為被修改的 address 建立新的記憶體空間。
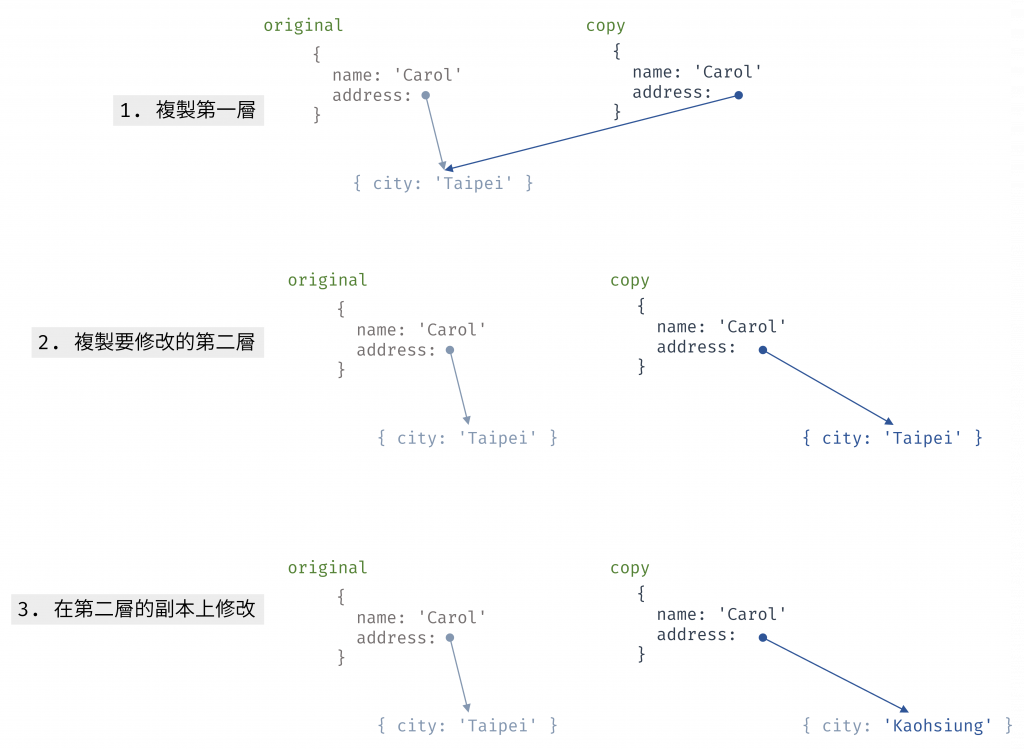
圖 3 只複製修改路徑的示意圖(資料來源: 自行繪製)
當一切資料都不可變時,這種共享是完全安全的。它能降低記憶體用量,也比每次都複製所有資料來得快。
可能有些人會覺得,不可變資料比可變資料消耗更多記憶體資源、操作較慢,以下是幾個《簡約的軟體開發思維:用 Functional Programming 重構程式 - 以 Javascript 為例》書中提及,可放心使用不可變資料的理由:
當我們的應用程式需要和外部系統(例如第三方函式庫、API 回應)互動時,我們無法保證它們傳來的資料是不可變的。為了保護我們純粹的、不可變的核心程式碼不受污染,我們需要採取「防禦性複製 (Defensive Copying)」的策略。
我們可以把程式想像成有兩個區域:
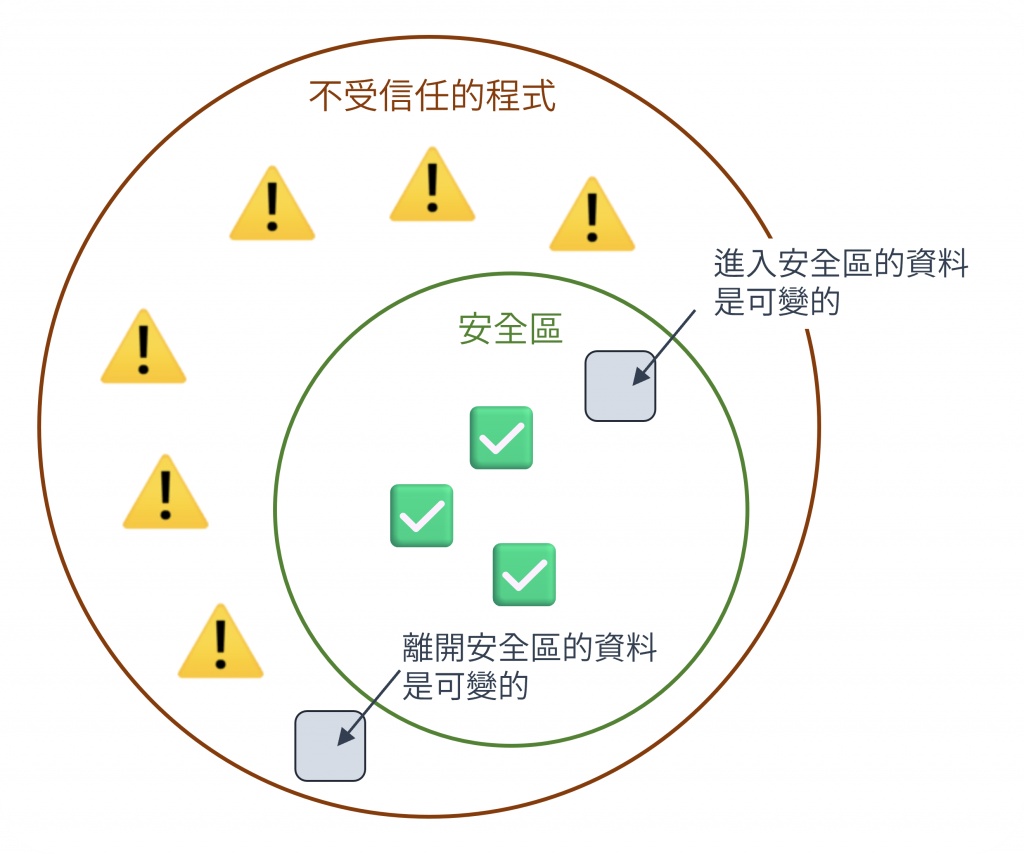
圖 4 程式分成兩個區域(資料來源: 自行繪製)
所有從安全區進入或離開的資料都可能被不受信任函式修改,這是一個潛在可變性,不受信任的函式可能保留安全區中的資料參照,隨時可能修改參照上的值。
我們前面提的寫入時複製並不適用於「不受信任的程式」,因為寫入時複製要求在修改時先拷貝,這代表我們要先知道修改在哪裡,才知道哪裡需拷貝,可是我們並不知道外部程式會在哪裡修改,無法得知哪裡需要複製。
因此針對這類「不受信任的程式」,因使用防禦型複製。
「防禦性複製」的策略很簡單:在資料跨越這兩個區域的邊界時,建立起防線。
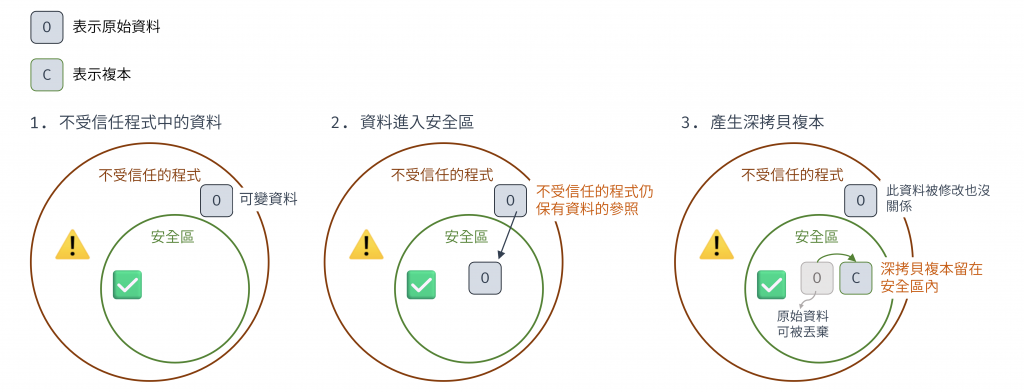
圖 5 資料從不受信任程式進入安全區需要做的防禦的示意圖(資料來源: 自行繪製)
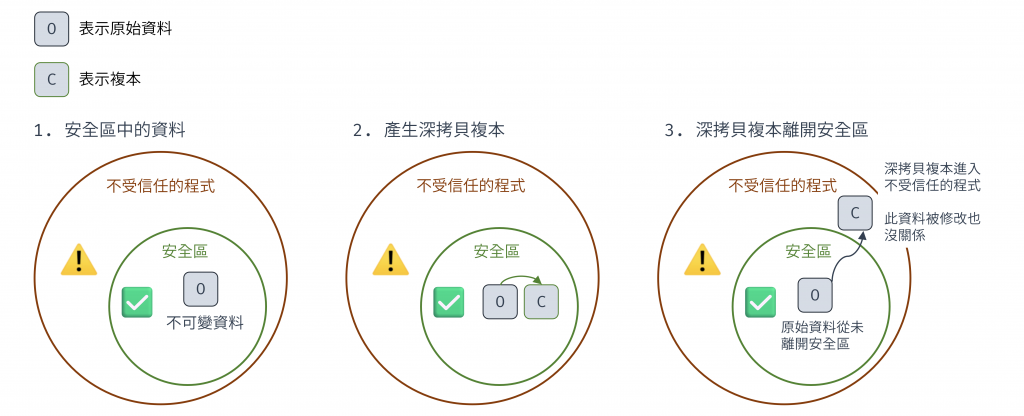
圖 6 資料從安全區到不受信任程式需要做的防禦的示意圖(資料來源: 自行繪製)
防禦型複製就是在資料進入和離開安全區時都做深拷貝,防禦外來程式碼造成的資料修改。
以下為程式碼範例:
// 假設這是從一個不受信任的 API 來的資料
const externalData = { user: { name: 'Dave' } };
// 1. 在邊界進行防禦性複製 (深拷貝)
// structuredClone() 是現代 JS 內建的深拷貝方法
const internalData = structuredClone(externalData);
// 現在可以安全地在我們的純函數中使用 internalData
//...
// 2. 當要將資料傳回給外部系統時,也先複製一份
function sendDataToExternal(data) {
const dataToSend = structuredClone(data);
// send(dataToSend);
}
實務上可使用的深拷貝工具,除了 JavaScript 原生的 structuredClone(),也可以使用像 Lodash 函式庫中的 cloneDeep() 來達成深拷貝。不過還是比較推薦使用原生的 structuredClone() 方法,目前 structuredClone 在各大執行環境都已經被支援,相關說明可參考 為什麼推薦用 structureClone 在 JavaScript 做深拷貝?。
寫入時複製是我比較常見的做法,之前沒聽過防禦型複製,也不知道什麼時候會用,這裡就補充一下《簡約的軟體開發思維:用 Functional Programming 重構程式 - 以 Javascript 為例》書中提到的一個防禦型複製應用。
日常開發常見的發送網路請求,他會以 JSON 格式進入 API,此 JSON 就是序列化客戶端的深拷貝複本,而當伺服器產生並回傳 JSON 的 response 時,此 JSON 也是序列化的深拷貝複本,因此資料進入或離開 API 都會被深拷貝,屬於一種防禦型複製。
防禦型複製有助於「服務導向(service-oriented)」、「微服務(microservice)」上設計方法不同的跨系統溝通。
寫入時複製與防禦型複製相同的地方在於都是用來確保不變性,但仍有一些不同處,以下面表格整理他們的差異和適合使用的情境。
| 寫入時複製(Copy-on-write) | 防禦型複製(Defensive copying) | |
|---|---|---|
| 何時使用? | 可自行控制程式實作時 | 需要和不受信任程式交換資料時 |
| 在哪使用? | 安全區內的所有函式皆使用是安全區安全的關鍵原因 | 資料進出安全區的地方 |
| 複製的類型 | 淺拷貝(資源需求較低) | 深拷貝(資源需求較高) |
| 基本步驟 | 1. 對欲變更的資料淺拷貝,產生複本2. 修改複本3. 傳回複本 | 1. 資料進入安全區時深拷貝2. 資料離開安全區時深拷貝 |
今天我們了解了純函數的核心理念:「不可變性」,以下整理幾個要點:

